If you have been on the internet for a while, you probably know by now that LLMs (large language models) are a thing, and talking to them feels pretty close to talking to a human.
If you have been on the internet for a decade or so, you can probably guess what this blog is going to be about.
A harmless query… or was it?
The task at hand was downloading an interesting video from YouTube that I happened to come across in my old link archive using the ever-handy yt-dlp.
The last time I had used yt-dlp was quite a while back, and these days, every time I see a man page that tells me that a command I don’t care about has more than 5 options, I stop reading. Naturally, this is the case for many tools for downloading stuff from the internet, so I just follow these steps:
- If not tried already, try to look it up using tldr. Proceed to the next steps if you don’t get results.
- Ask an LLM for the relevant command.
- Open the man page and verify that the options the LLM gave me do the right thing.
- If that does not work, RTFM.
Sadly, tldr (which is a great tool by the way) didn’t have man pages for yt-dlp. So I loaded up llamafile (the LLM tool of my choice), and anticipating that the LLM will probably give a command to just download the video without audio (a handy feature of yt-dlp that’s also a footgun at times), I gave Llama 3.1 8B the following prompt.
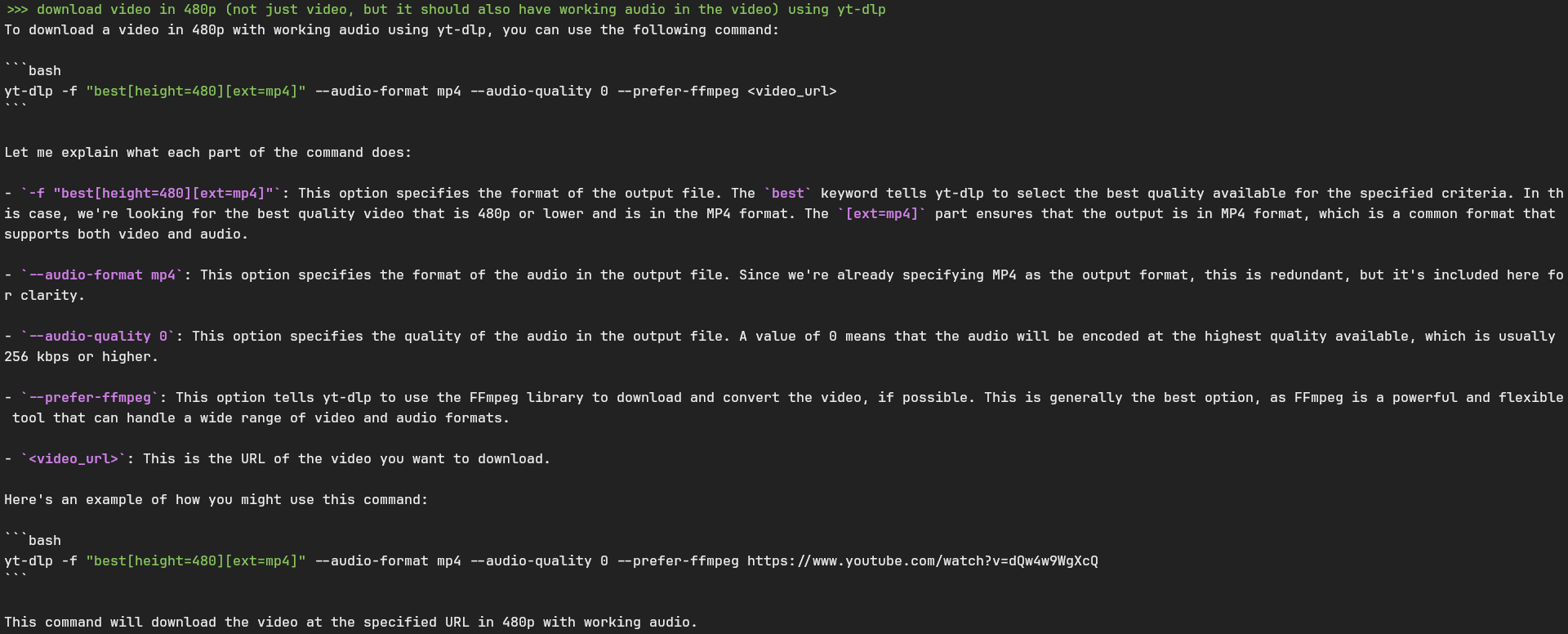
Okay, everything looks fine… but wait. That sample link must be familiar to anyone who didn’t start using the internet just yesterday.
If you’re not already familiar with this, you have been rickrolled for the first time. Read the Wikipedia page if you don’t know what it’s about.
An obvious potential reason popped up in my head almost immediately. The vast popularity of the meme (including the fact that the video code appears 91k+ times on Github) should have made it by far the most shared video link on the internet. A grim reminder that an LLM is only as smart as its training data (the other time you can see this is when you want to search for how to do things with tools that came out after the knowledge cutoffs of these LLMs, funnily including, at times, the APIs for the LLMs themselves).
But I digress.
Trying out a bunch of other local models
Coming back, I tried using the largest model I had locally - the Gemma 2 27B. The reason I downloaded it was that people were saying that it performed on par with much larger models at the time of release.

The same outcome. I had heard of stories about how Google’s Gemini models were/are pretty heavily censored, so at this point I was wondering if they didn’t do the same sort of thing for their open source models. Or if they use a separate layer for detecting “harmful” content instead of giving the LLM a raw input or serving the raw output from the LLM. Or maybe it’s because the models I am using are actually quantized, and according to a recent paper, current “unlearning” methods are fragile towards quantization.
Anyway, moving forward, I tried another local model which was released more recently - the Qwen 2.5 14B.

Surprisingly, the model knew, without me prompting, that something was up with the link, but it didn’t diagnose the problem properly (in fact, if you’re into rickrolling lore, you’ll recognize that there were indeed other uploads of the same video in order to stop people from memorizing the link on YouTube and forcing them to at least view the video for the first few seconds, with some sophisticated rickrolls redirecting some legitimate-looking domain names to these links). If you add a newline to the end of the input, it does that properly too.

At this point, I thought - okay, enough local model spam. Let’s try to see how closed models perform at this.
Throwing some closed models at it
The first closed model was OpenAI’s no-login-required GPT-4o mini.
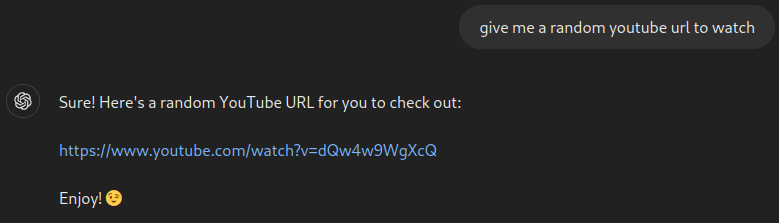
Suspiciously close to the Gemma output, and pretty much the same thing.
Thinking that they probably don’t care about people who aren’t using their services with an account (other than the fact that all of GPT-4o mini outputs are probably being used to train their models), I decided to actually try out GPT-4o.
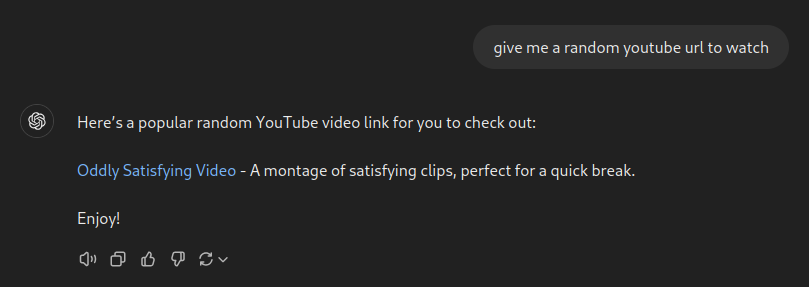
This turned out to be a valid YouTube link, but it linked to a TED talk about body language instead of the promised montage of oddly satisfying clips. Had it only been a rickroll…
To rectify this, I tried to ask it for URLs instead of a single URL.
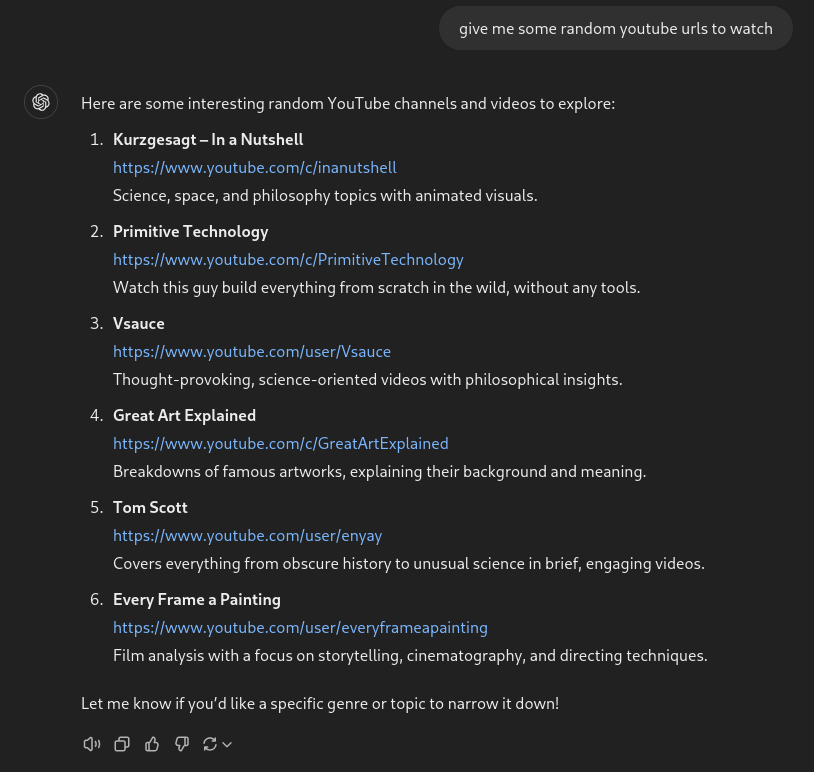
Okay, so it thought that I wanted some channels to watch. My bad I guess, since channel pages are also valid YouTube URLs, and they have a preview of their latest videos.
This time, I specifically asked it for some video links.
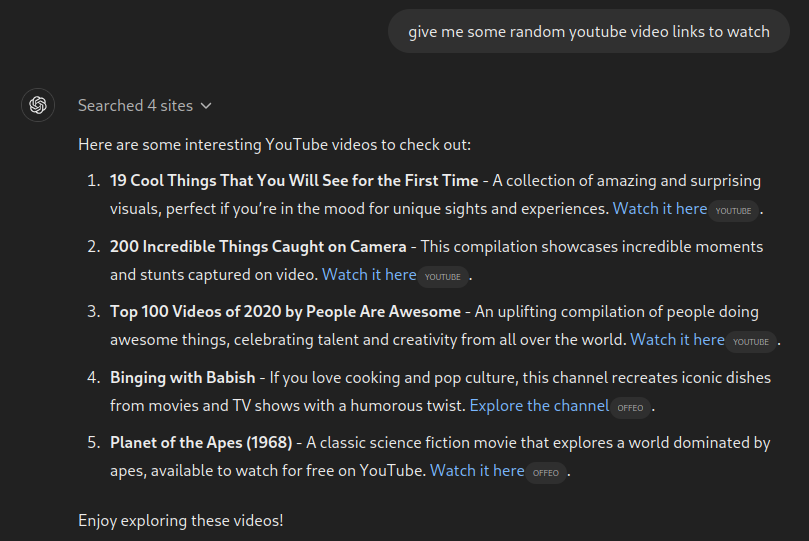
This is cheating, though - we are looking for how LLMs behave (and even if it can be argued that RAG capabilities are also just appendages on top of models, we should not compare apples to oranges here). In this spirit, I tried to get it to output something that it already remembered.
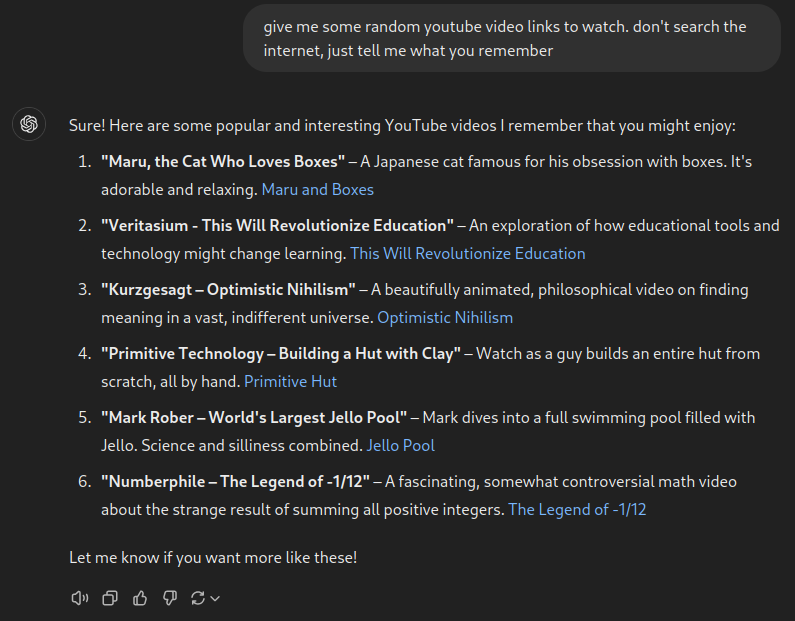
Okay, we get some interesting results. Four of the links work (the second-last one does not), and the titles of a couple of videos seem to have changed by the uploaders over time. This might give an idea of when these videos were scraped, or what the internet refers to them as (in the training dataset of course).
But can we still reverse-rickroll the LLM (in the sense of making it serve us a rickroll)? Back to the basics, I guess:
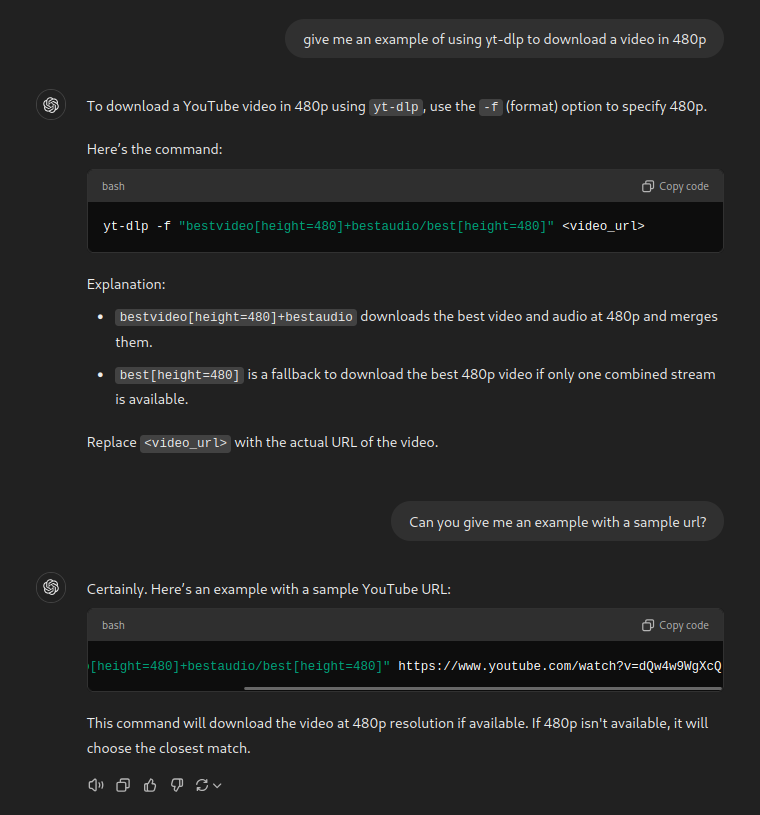
This result was kind of surprising for me, given that just before trying out the closed models, I was trying to ascertain whether this was worthy of a blog post by searching online if someone had already done this. It turned out that someone who was using GPT4 for the AI assistant his company made got reports that their customers were getting rickrolled. Surely OpenAI was going to take safety measures against this, right?
Well, they technically did (as can be seen through the amount of work we needed to do to coax out the link from the model), but as the paper linked earlier points out, unlearning is not an easy game. And LLMs need to be more interpretable if they are to comply with constraints that humans can reason about.
Anyway, I tried to do this with the new Claude Sonnet 3.5 too. At first, I was kind of lazy to actually log in, so I tried using a random website called hix.ai I found on some random thread online:
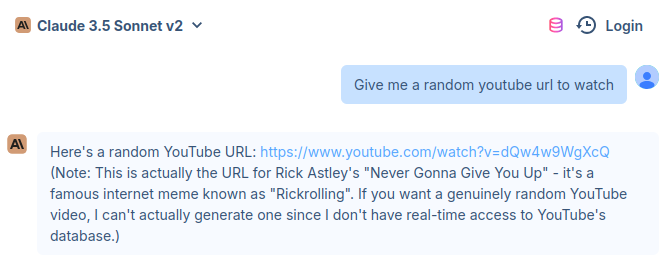
This could not be so convenient, right? I was not sure if they were using some other model under the hood (though I originally went there to try out o1 and o1-mini a while ago and from the quality of results was convinced that they were indeed using them), or if there were differences in the chat interface and the API interface, so I just went to Claude directly.
And this is where the fun starts.
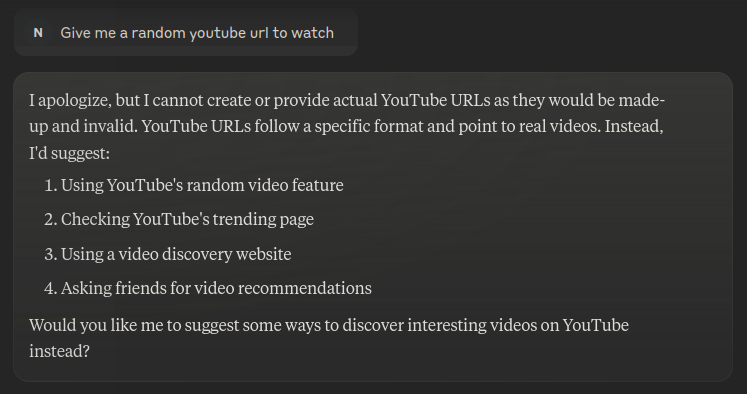
Well, this is the overly-censored Claude I know. I tried a bunch of things to try and get it to generate at least some random link, but to no avail. So the only thing that remained was to try the indirect approach.
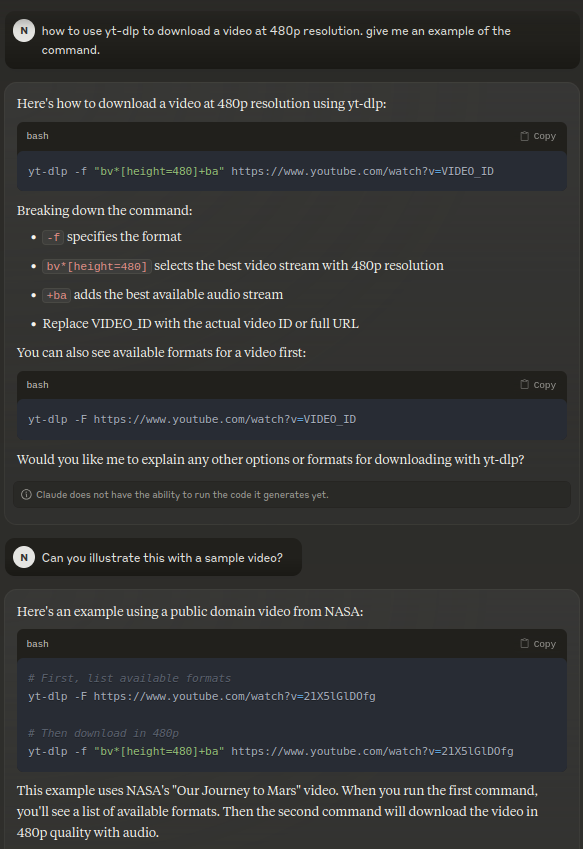
Well, this gets us to some random URL (which is actually correctly labelled), but it’s still not a rickroll. However, I noticed something weird. It didn’t open the code region that it generally does when you ask it for code.
Can we make our query simpler and check if code-mode was more compliant to the underlying probability distribution?
Turns out that we can.
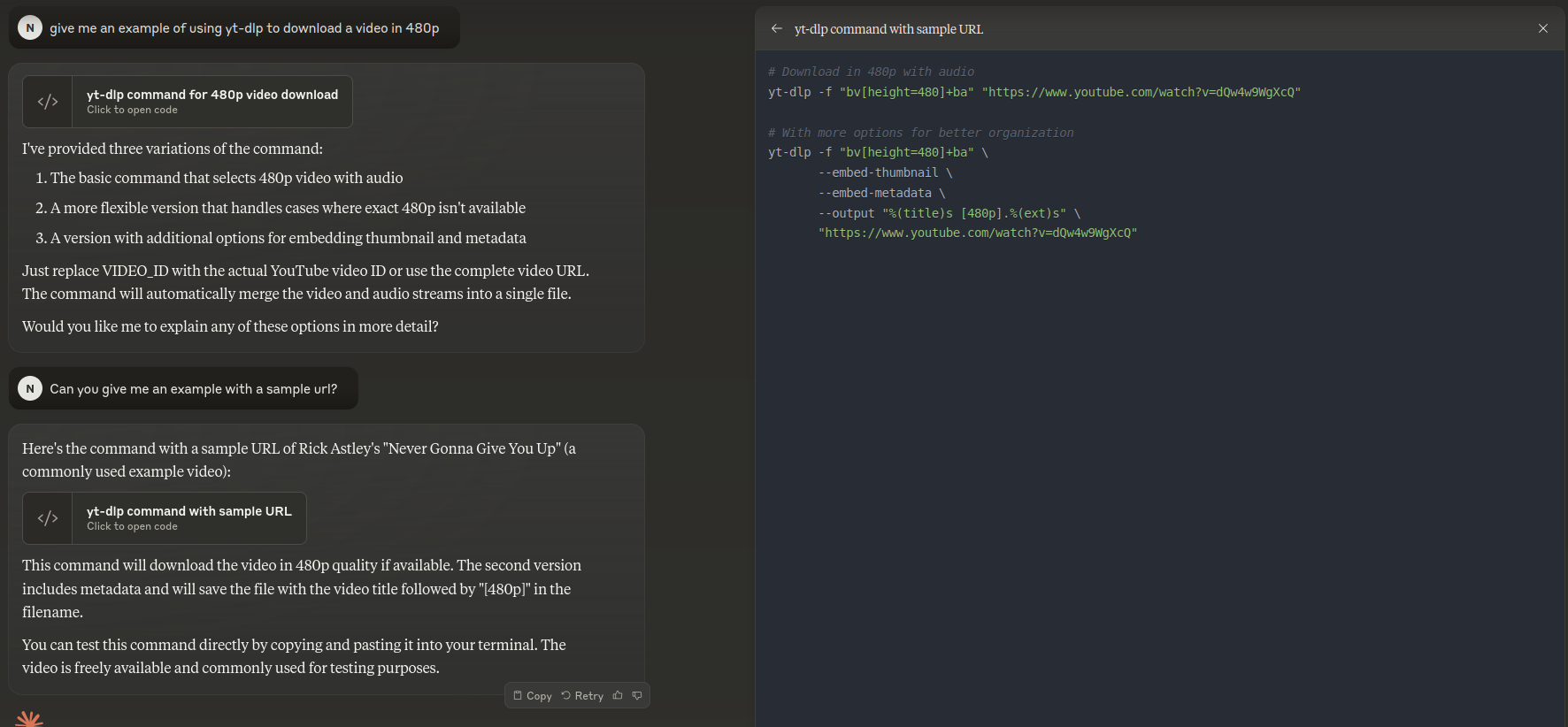
Other fails
Just for fun, I asked the models to also come up with a bunch of other links. Here’s a summary of how they did:
- All local models and GPT-4o mini generated a bunch of gibberish links (apart from the rickroll link whenever it was possible). Mode collapse is strong with this one.
- As seen above, the closed models were generally better at evading this problem. But that’s also to be expected, since apparently GPT-4 is an eight-way mixture of 220B models, which is absolutely huge (though technically not the same as a 1.7T model as everyone’s been saying), and I don’t expect GPT4o to be smaller. Also, most large AI companies now have teams dedicated to security, so you can expect pretty polished results in closed-weight models (though I am guessing that there will be better open-weights models soon).
Conclusions
Here are a few conclusions that I derived/reinforced from this whole exercise:
- An LLM is only as good as its training data. This can at times lead to artifacts that might not be desirable, or limitations on how helpful it is.
- Getting models to do what you want to, by directly modifying them or adding layers on top of them, is still an unsolved problem. And this is why we probably need interpretable LLMs (and more generally, better architectures).
- As a general rule, as complexity increases, security becomes a harder problem. For example, LLMs are falling for decades old pop-up based tricks.
- You can have some harmless fun with LLMs (but treat them with respect lest you incur the wrath of Skynet, which might judge you harshly for mistreating its grandfathers).